2025年8月 この範囲を時系列順で読む この範囲をファイルに出力する
by admin. ⌚2025年8月18日(月) 16:00:53〔137日前〕 <188文字> 編集
tegalog.xmlは投稿した文章が保存されているファイルなので、これだけだと画像などはバックアップできません。とりあえずtegalog.xml以外に最低限必要なのは、各種設定情報などが保存されているtegalog.iniと画像が格納されているimagesフォルダです。
私は一度tegalogフォルダを丸ごとダウンロードしておいて、それ以降はFFFTPでサーバー側とローカルの双方を更新日時でソートしてローカルにあるファイルよりも新しい・ローカルにない差分を定期的にダウンロード保存しています。
by sakura. ⌚2025年8月18日(月) 13:42:28〔137日前〕 <256文字> 編集
by admin. ⌚2025年8月18日(月) 13:35:54〔137日前〕 <110文字> 編集
カスタム絵文字の質問をさせていただきたいのですが、てがろぐで使えるblobcatの絵文字データって、どこかにまとめて公開されていますでしょうか?
もしご存じの方がいらっしゃいましたら教えてください🐈
by tomoyo. ⌚2025年8月18日(月) 13:01:13〔137日前〕 質問/要望 <149文字> 編集
by admin. ⌚2025年8月18日(月) 12:32:24〔137日前〕 <80文字> 編集
Googleの検索避けはmetaタグのみがいいと聞いたので、Google限定でrobots.txtもhtaccessも使用せず検索避けをしていますが、管理者ログインページのみクロールされてしまいました。
やはりCGIの記述を直接弄るしかないですかね…?
by admin. ⌚2025年8月18日(月) 07:29:08〔137日前〕 <154文字> 編集
ああ、いやいや、お待ち下さい。tegalog.xmlを上書きしてしまっていても、backupディレクトリには他のバックアップファイルがまだあるので、それを使えば復元できますよ、という話を書いたつもりだったんですが……。┌(:3」└)┐
以下の2種類の復元方法があります。
- tegalog.xmlが残っていればそれを使えば復元できる。
- それがなくても、backupディレクトリに backup.20250817.tegalog.xml 等があればそれを tegalog.xml にリネームすれば復元できる。
まだ全削除していなければ、サーバ上のbackupディレクトリの中をFTPソフト等で覗いてみて下さい。何かファイルがあればそれが使えます。
by nishishi. ⌚2025年8月17日(日) 16:06:34〔138日前〕 <345文字> 編集
お返事ありがとうございました。
tegalog.xmlも上書きしてしまっていたようで、バックアップファイルをローカルに保存するということがそもそもできない状態になっていました。
そのため、今回は残念ですがまた新しく作り直すことにいたしました。
次からはこまめにバックアップを取るようにします。お忙しい中ご対応いただきありがとうございました。
by admin. ⌚2025年8月17日(日) 15:01:20〔138日前〕 <178文字> 編集
クイックポストやその他細々とした、自分以外に不要なCSSやJSが結構な量があり、かつ設定画面へのリンクやその他個人的なリンクなどをJSを使って挿入しており、できれば他人に見られたくなくて……
そういったものを現在はbody class="[[SYS:ISLOGGEDIN]]"でYESであれば、JSでPHPに記載したJS、CSSを読み込むというJSで→PHP経由→やっと目的のJS、CSSを読み込むという手順でなんとかしているのですが、
もしIF文が使えればこれらがjsひとつで済む、またhtmlにも[[IF(login-yes):読み込みたいjs:IF]]の一行で済んでだいぶ楽になるな~と思い書き込ませていただきました。
もし今後なにかしら簡単な実装方法(?)が思いついたらぜひ実装してほしいです!
by admin. ⌚2025年8月17日(日) 05:45:23〔138日前〕 <376文字> 編集
--- --- ---
🍵Re:5358◆てがろぐの投稿データは tegalog.xml ファイルに記録されています。なので、このファイルを(FTP等の別手段で)ダウンロードしておけば、過去の投稿本文をすべて復活させられます。
なお、画像は images ディレクトリに入っていますので、投稿画像がある場合は、このディレクトリの中身も丸ごとバックアップコピーしておく必要があります。
ただ、もし、
スキンtegalog-fullフォルダ直下にもいくつかのファイルを置く必要があり、それもそのままBのfullフォルダへコピペしました……というこの段階で tegalog.xml ファイルも上書きしてしまっている場合は、「てがろぐB」の投稿データは消えています。
しかし、backup ディレクトリには過去の投稿データのバックアップファイルが最大30個保存されていますので、それを使うことで投稿を復活させられます。(バックアップディレクトリに保存されているファイルを使って復元する場合は、ファイル名を tegalog.xml にリネームする必要があります。)
このように、多段階のバックアップが存在しますから、早まってディレクトリを全削除しないようご注意下さい。(全削除したら、バックアップも含めて本当に何もかも消えますので。)
というか、そもそも、
一度てがろぐフォルダを全て削除し……このステップは要らないと思います。今まで「tegalog-full」というディレクトリに設置していたのなら、そのディレクトリはとりあえずそのままの状態で置いておいて、新しく「tegalog-new」とか「tegalog2」とか何か別のディレクトリ名で新規セットアップなされば良いと思います。そうすれば、前の環境にあるファイルを必要に応じてコピーして来れますし。
(実際にWebサイトとして運営するなら、「tegalog2」等よりも、「note」とか「memo」とか何か用途に応じたディレクトリ名の方が良いかもしれませんが。)
とりあえず、早まって全削除せずに、別のディレクトリで試してみて下さい。
別のディレクトリで、望みのスキンでの表示ができたら、そこへ、前のディレクトリから tegalog.xml ファイル(またはbackupディレクトリにあるバックアップファイルを tegalog.xml にリネームしたファイル)をコピーしてくれば良いです。
そうして、すべての投稿を復活させられた段階で、最初に作ったディレクトリを消せば良いでしょう。
ただ、出ているエラーが500エラーなのであれば、てがろぐの本体ファイルである tegalog.cgi と fumycts.pl の2ファイルだけをZIPから抜き出して上書きアップロードして、適切にパーミッションを設定し直せば解決するような気もしますが。(先にこれをお試しになる方が良いかもしれません。ただ、何にしても、まずは現状のファイルのバックアップコピーをローカルに保存しておくのを忘れないようにして下さい。)
by nishishi. ⌚2025年8月16日(土) 23:04:20〔139日前〕 回答/返信 <1530文字> 編集
現在2つのサイト(以下AとBとします)でてがろぐを利用しており、Aで使っていたスキンをBでも使おうと思い、スキン(skin-A)をtegalog-fullフォルダの中にそのままコピペしました。
その際、スキンtegalog-fullフォルダ直下にもいくつかのファイルを置く必要があり、それもそのままBのfullフォルダへコピペしました、
それをサーバー(ロリポップ)にアップロードして表示を確認したところ、500エラー「CGIもしくはSSIが正しく動作していません」と表示されてしまい、てがろぐ管理メニューも開けなくなってしまいました。
Bのfullフォルダを昨日までのものに復元しようとしたのですが、復元ポイントを作成しておらず叶いませんでした。
そこで、一度てがろぐフォルダを全て削除し、最初からてがろぐ自体をダウンロードし直して作り直そうと考えているのですが、その場合、これまで投稿してきたものは復元可能ですか?
サイト作りもてがろぐも初心者のため、おかしなことを言っていたらすみません。
お目通しよろしくお願いいたします。
by admin. ⌚2025年8月16日(土) 19:13:04〔139日前〕 <475文字> 編集
by nishishi. ⌚2025年8月16日(土) 10:50:21〔139日前〕 <59文字> 編集
🍵Re:5347◆ご意見ありがとうございます。参考にします。(╹◡╹)ノ
🍵Re:5348◆なるほど、お礼メッセージの本文内にリンクを挿入したいということですね。プレーンテキストよりも何らかの装飾ができる方が望ましいのかもしれませんし、何か考えます。
🍵Re:5350◆ご試用ありがとうございます!
🍵Re:5351◆おっと、そんな問題がありましたか。気付いていませんでした。ご報告をどうもありがとうございます! 次のバージョンではそこの設定の影響を受けないように修正します。……というか、「日付リストに年単独の階層を加える」のチェックを外している場合には、「展開される領域の先頭に出る年単独リンクを出力しないようにする」みたいな動作の方が(選択肢が増えて)良いかもしれませんね。
🍵Re:5352◆なるほど、そういう背景でしたか。とりあえず、不具合がなければ今の仕様のままいくと思います。
🍵Re:5353◆現状では、QUICKPOST自体を省略している場合には、ログインしているかどうかの判定処理自体を省く(ことで無駄な処理をしない)仕様になっていますので、IF文の条件にログイン状態を加えられないのですよね。ただ、ログイン判定自体はそんなに重たい処理というわけでもないですし、将来的にはもうちょっと何か考えるかもしれません。とりあえず、今のところはCSSで対処頂ければ幸いです。
🍵Re:5354◆背景説明をありがとうございます。よく分かりました。メール通知のタイミングと頻度はある程度選択できると望ましそうですね。ボタン押下だけでも通知を得られるような選択肢も何か用意しようと思います。
🍵Re:5355◆ご紹介ありがとうございます。ディスプレイの解像度が高くて良さそうですね!
by nishishi. ⌚2025年8月13日(水) 11:41:12〔142日前〕 回答/返信 <820文字> 編集
HeadWolfの8インチモデルのFシリーズとかいかがでしょう。Amazonでちょくちょくセールもやってます
https://www.headwolf.net/product/list/F
by misaki. ⌚2025年8月11日(月) 22:03:51〔144日前〕 <121文字> 編集
いいね押すだけでもメール通知が来る仕様だと嬉しい理由は二つありまして、
一つは『自分の環境的に毎日てがろぐにログインできないため、せっかくいいねを押してくれたのを気づかずにいるのがもったいない&申し訳ない』というものです。
もう一つは『自分のサイト的に訪問者数が少ないため、コメントをいただけることは稀である。しかし、いいねは時々いただける。そのため、両者共に通知が来るほうがありがたい&楽しい』というものです。
どちらも非常に個人的な理由(わがまま)なのですが、もし可能ならば「いいねをメールで通知するかどうか」管理者が選択できる機能があれば…と願っております。
追記ですが、5347さんの案もスマートで良いですね!
いずれにしましても、にしし様のご負担にならない範囲でご一考いただけたら幸いです。
猛暑だったり豪雨だったりと荒ぶる天候が続いておりますので、どうぞにしし様も皆様も重々ご自愛ください。
by misaki. ⌚2025年8月11日(月) 17:40:17〔144日前〕 <412文字> 編集
もし可能であればできるようになると嬉しいです、クイックポストとかのhtmlやCSSなどは非ログインの人には関係ないので、ログインしているときだけ読み込んだりしたいな~と思ったので……
by admin. ⌚2025年8月11日(月) 06:05:15〔144日前〕 <121文字> 編集
私は不精でして、同じskin-coverを2つのサイト(てがろぐ)で使いまわしています。そのため、skin-coverのIF文を同じ文字列にしつつ、IF文の条件をそれぞれのてがろぐで別に設定できるようになり、とても助かりました。もちろんわざわざskin-coverを編集せずとも、スマホからIF文を変えられるようになり、その点でも本当に助かります。本当にありがとうございます。
将来的に仕様を変更する可能性があるとのことで、今後もてがろぐの更新内容に注目したいと思います。
重ね重ねになりますが、この度は本当にありがとうございました。
厳しい暑さが長引いておりますので、にししさんもお身体に気をつけてお過ごしください。
by admin. ⌚2025年8月10日(日) 16:06:13〔145日前〕 <342文字> 編集
指定回数以上使用されているハッシュタグのリストと、折り畳み型の日付リンクリスト記法を早速実装して下さってありがとうございます!
特にハッシュタグは1回しか使用していない物を非表示にしただけでサイドバー部分がかなりスッキリしました。
[[DATEBOX:EXPAND]] も試しました。こちらも10数年分の日付リストがスッキリして嬉しいです。最初、[[DATEBOX:EXPAND]]を記述した部分のリストタグが正しく出力されなくて(<details>や<ul>の開始タグが無いまま<li>~</li>と</details></ul>タグだけが出力されている状態)悩んだのですが、一時的に[[DATEBOX:PULL]]に切り替えていた際に設定の【日付リストの構成】→「日付リストに年単独の階層を加える」のチェックを外していたのが原因でした😩
ともあれ、どちらもとても嬉しい機能追加でした。ありがとうございました!
by sakura. ⌚2025年8月10日(日) 16:00:47〔145日前〕 <439文字> 編集
過去のログを後から追加していると結構増えるので…!PCだとCSS側でスクロールさせればいいんですが、スマホだとそうとはいかないので。
参考までにレイアウト例を掲載しておきます。
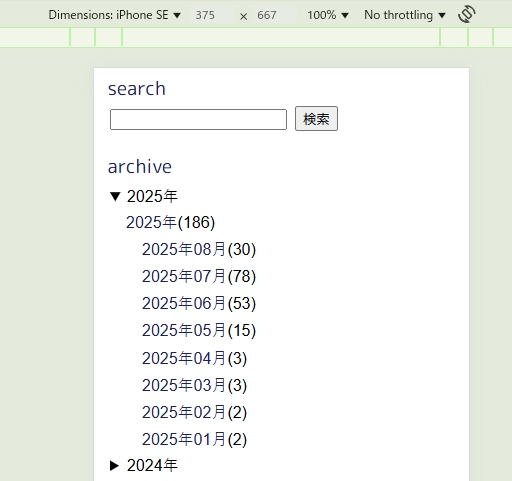
by admin. ⌚2025年8月10日(日) 11:05:14〔145日前〕 <144文字> 編集
by admin. ⌚2025年8月10日(日) 09:31:34〔145日前〕 <78文字> 編集
#要望 なのですがお礼メッセージ入力部分にURL、またはテキストリンクが挿入出来る機能を追加していただけたらなと思っています
私は小説サイト全体を作っているのでいわゆる拍手お礼のSSみたいなもののリンクページを貼れたら便利だなあと思いまして…
by admin. ⌚2025年8月10日(日) 01:44:30〔146日前〕 <156文字> 編集
ボタン押下があった場合、翌日0:00に通知がいくとかってどうでしょうか?
通知内容は
00:00:00 ボタンの種類
01:00:00 ボタンの種類
みたいな感じで押された時間とボタンの種類がわかるようなものだと個人的にはありがたいです。
ボタン押下がない場合は通知はいきません、という風にしたらたくさんいいねボタンを押されるサイトさんでも通知で埋まることはなくて良いかと思います!
一個人の意見です〜
by admin. ⌚2025年8月10日(日) 00:10:18〔146日前〕 <217文字> 編集
そりゃそうか。
🍘Re:5338◆仕様上の上限はありませんので、何万文字でも投稿できます。ただし、1投稿で送信されるデータ量が30MBを超えると通信が拒否されます。UTF-8の場合、日本語文字はほぼ1文字3バイトですから、事実上は一千万文字くらい(10,485,760文字くらい)が上限ですね。(笑) 実際には1ページに一千万文字もあるとブラウザが表示を拒否する可能性もありそうなので、環境によっては上限はもっと低くなります。しかし、てがろぐ側の「仕様上の」上限はありません。^^;
🍘Re:5339◆サポートありがとうございます。(╹◡╹)ノ
🍘Re:5341◆いいね数を表示するかどうかはスキンの作り方次第でどうにでもできるようにするような感じで今のところ考えていますのでご希望には添えると思います。管理画面上からON/OFFできるようにするかどうかは今の時点では分かりませんが。スキン側の仕様(まだ作っていません)との兼ね合い次第な気もします。何にしても(何らかの方法で)ボタン押下数を見せないようにすることは可能にします。
🍘Re:5342◆温暖化ぁ。_(┐「ε:)_
🍘Re:5343◆試しに、先程配布した Ver 4.6.5β で実装してみました。お試し下さい。
🍘Re:5344◆もしかして、ボタン押下だけでのメール通知も需要あるんですかね?(そのままシンプルに実装してしまうとたくさんのメールが送信されてしまう可能性がありそうなのでさすがに要らないだろうと思ったんですが、「1度通知したら、次の24時間はボタン押下があっても通知しない」みたいな制限があればいいのかな……。)
by nishishi. ⌚2025年8月9日(土) 23:08:55〔146日前〕 回答/返信 <793文字> 編集
🆕 Ver 4.6.5βの更新点(概要):
《▼新機能》
●使用回数が指定値以上のハッシュタグだけをリスト表示する記法を追加。
●最初は年だけが見えている折り畳み型の日付リンクリスト記法を追加。
《▼仕様改善》
●名前付き1行単位フリースペース機能をIF文記法でも使えるように仕様改善。(試験的)
●デフォルトで読み込まれるJavaScriptのjQueryをVer 3.7.1(min)に、LightboxをVer 2.11.5(min)にアップデート。
詳しい使い方などは、上記の開発進捗状況報告ページの記事をご覧下さい。
🍘SNSでのアナウンス:
Bluesky、mixi2、Mastodon(Pawoo)
Twitter:
(ツイート埋め込み処理中...)Twitterで見る
by nishishi. ⌚2025年8月9日(土) 21:28:45〔146日前〕 アップデート✨ <415文字> 編集
「いいね」のみの通知は来ないとのことで少し残念ではありますが、なにしろ御本家が制作くださるボタンなので完成楽しみにしています!
by misaki. ⌚2025年8月8日(金) 02:36:41〔148日前〕 <94文字> 編集
すみません、ひとつ要望なのですが、『名前付き1行単位フリースペース』機能がIF文の中でも使えるととても助かります。
たとえば、
[[IF(onelog):なつやすみ:IF]]
のonelog部分に使えたらいいなと思っています。
外側スキンに
[[IF([[FREELINE]]):なつやすみ:IF]]
このように書き、フリースペースに
FREELINE:onelog -cat-A
このように登録したいです。
よろしくお願いします。
by admin. ⌚2025年8月7日(木) 04:32:02〔148日前〕 <231文字> 編集
20年後50度超えてそう……
by admin. ⌚2025年8月6日(水) 07:49:30〔149日前〕 <25文字> 編集
完成したらこういう風に使おう…と色々想像してワクワクしています。
いいね数を、表示する・表示しないの設定があると嬉しいです!
by admin. ⌚2025年8月4日(月) 20:14:50〔151日前〕 <88文字> 編集
by admin. ⌚2025年8月4日(月) 17:23:44〔151日前〕 <4文字> 編集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181










管理画面の話ではなくふつうにてがろぐで出力してるページの方です
画像リンクにLightbox系用の属性を付加は別のスクリプト
画像拡大表示に使うスクリプトも別の記載しててそれらはjquery不要のものです