 てがろぐ
- Fumy Otegaru Memo Logger -
てがろぐ
- Fumy Otegaru Memo Logger -
カテゴリ「回答/返信」に属する投稿[767件]
投稿欄にスクロールバーが出ているとき、文字装飾機能や「何でも簡単挿入機能」等を使って文字列を挿入すると、一部のブラウザで最下端までスクロールされてしまう問題を解消してみた Ver 4.8.1β(未配布)の動作テスト。
たぶんこれで解消したのではないかと思いますけども、どうでしょうかね……? >>5825,5826,5827/R
たぶんこれで解消したのではないかと思いますけども、どうでしょうかね……? >>5825,5826,5827/R
🍫てがろぐをusamimi.infoサーバでお使いの場合、設定画面で「設定を保存する」を押すと403 Forbiddenエラーが出ます。
これは、サーバ側で導入されたセキュリティモジュールが、特定のルールに抵触することを検出した結果のようです。
サーバ管理者さんへ直接ご連絡頂けば、ご使用のアカウントに限って当該ルールの無効化をして頂け、それによって保存処理が可能になるようですので、usamimi.infoサーバをご使用の方々はお手数ですがサーバ管理者さんに問い合わせてみて下さい。
🍫Re:5834◆実験をどうもありがとうございます! おかげさまで状況がよく分かりました。
初期状態でもそうなるのであれば、usamimi.infoサーバと同じ環境を用意して、ログを確認しながら1つずつ実験してみる以外にないので、サーバ側で当該ルールを無効化して頂くのが現実的だと(少なくとも今のところは)思います。
🍫てがろぐCGIのサーバ別セットアップ方法解説内の「usamimi.infoでのセットアップ手順」にも『usamimi.info特有の補足情報』に情報を加えておきました。
これは、サーバ側で導入されたセキュリティモジュールが、特定のルールに抵触することを検出した結果のようです。
サーバ管理者さんへ直接ご連絡頂けば、ご使用のアカウントに限って当該ルールの無効化をして頂け、それによって保存処理が可能になるようですので、usamimi.infoサーバをご使用の方々はお手数ですがサーバ管理者さんに問い合わせてみて下さい。
🍫Re:5834◆実験をどうもありがとうございます! おかげさまで状況がよく分かりました。
初期状態でもそうなるのであれば、usamimi.infoサーバと同じ環境を用意して、ログを確認しながら1つずつ実験してみる以外にないので、サーバ側で当該ルールを無効化して頂くのが現実的だと(少なくとも今のところは)思います。
🍫てがろぐCGIのサーバ別セットアップ方法解説内の「usamimi.infoでのセットアップ手順」にも『usamimi.info特有の補足情報』に情報を加えておきました。
ラスクを食べました。おいしい。
🍞Re:5828◆WAFの検出ログには、「どんなルールに抵触したためにブロックされたのか」という情報が含まれています。それを見れば、「そのルールに抵触しないような方法に変更可能か?」という点を検討できます。そういった情報が得られない場合は、そもそも何が問題なのかが分からないので、対処のしようがないのです。(※そもそも、現時点ではWAFが原因かどうかもハッキリはしていないわけですが。)
これだけ異なる方が同じ現象に遭遇なさっているなら、サーバ側の何かの設定等が(ある時点から)問題になったのでしょうね。
エラーログ等から判断ができなければ、サーバ管理者さんに究明を依頼するほかなさそうな気がします。
🍞Re:5828◆WAFの検出ログには、「どんなルールに抵触したためにブロックされたのか」という情報が含まれています。それを見れば、「そのルールに抵触しないような方法に変更可能か?」という点を検討できます。そういった情報が得られない場合は、そもそも何が問題なのかが分からないので、対処のしようがないのです。(※そもそも、現時点ではWAFが原因かどうかもハッキリはしていないわけですが。)
これだけ異なる方が同じ現象に遭遇なさっているなら、サーバ側の何かの設定等が(ある時点から)問題になったのでしょうね。
エラーログ等から判断ができなければ、サーバ管理者さんに究明を依頼するほかなさそうな気がします。
昼食はピザ。🍕🍕🍕
🍕Re:5822◆ご要望をありがとうございました。Webコミックを埋め込もうという発想がなかったので(公式に埋め込み機能が提供されている事実も知らなかったので)おかげさまでなかなか面白い機能を加えられました。
🍕Re:5823,5824◆お使いのサーバでは「WAFの検出ログ」は閲覧可能でしょうか? てがろぐの設定を保存した瞬間の時刻に、WAF側でどんな検知がされた結果として通信がブロックされたのかが分かると、何らかの調整ができるかもしれません。
なお、WAFのON/OFFをコントロールパネル等から変更可能でしたら、一時的にWAFをOFFにしてみた上で、てがろぐの保存操作を試してみて頂くと、WAFが原因なのかどうかがハッキリします。
🍕Re:5825,5826◆なるほど、PC版ブラウザでもChromeやEdgeを使うとおっしゃる動作になりますね。私は普段(特に開発用途には)Firefoxを使っているので気付きませんでした。てがろぐ側が編集領域に何かを挿入する際には、実際には「編集領域内の全文を置き換える→カーソル位置を元に戻す」という2段階の処理をしているのですが、どうやらそのとき『スクロール位置も一緒に戻してくれるブラウザ』と『スクロール位置はプログラム側が面倒を見ないといけないブラウザ』とがあるようです。そこまで思い至っていませんでした。
次のバージョンでは対処しますので、もうしばらくお待ち下さい。
とりあえず、PCではFirefoxをお使い頂くと現状でも問題は起きません。または「編集最大機能を使ってできるだけスクロールが発生しにくいようにする」という対処方法もあるかもしれませんが。
ご報告をどうもありがとうございます。
🍕Re:5822◆ご要望をありがとうございました。Webコミックを埋め込もうという発想がなかったので(公式に埋め込み機能が提供されている事実も知らなかったので)おかげさまでなかなか面白い機能を加えられました。
🍕Re:5823,5824◆お使いのサーバでは「WAFの検出ログ」は閲覧可能でしょうか? てがろぐの設定を保存した瞬間の時刻に、WAF側でどんな検知がされた結果として通信がブロックされたのかが分かると、何らかの調整ができるかもしれません。
なお、WAFのON/OFFをコントロールパネル等から変更可能でしたら、一時的にWAFをOFFにしてみた上で、てがろぐの保存操作を試してみて頂くと、WAFが原因なのかどうかがハッキリします。
🍕Re:5825,5826◆なるほど、PC版ブラウザでもChromeやEdgeを使うとおっしゃる動作になりますね。私は普段(特に開発用途には)Firefoxを使っているので気付きませんでした。てがろぐ側が編集領域に何かを挿入する際には、実際には「編集領域内の全文を置き換える→カーソル位置を元に戻す」という2段階の処理をしているのですが、どうやらそのとき『スクロール位置も一緒に戻してくれるブラウザ』と『スクロール位置はプログラム側が面倒を見ないといけないブラウザ』とがあるようです。そこまで思い至っていませんでした。
次のバージョンでは対処しますので、もうしばらくお待ち下さい。
とりあえず、PCではFirefoxをお使い頂くと現状でも問題は起きません。または「編集最大機能を使ってできるだけスクロールが発生しにくいようにする」という対処方法もあるかもしれませんが。
ご報告をどうもありがとうございます。
今日は暖かい日でした。
🍘Re:5820◆設定の保存以外の機能は問題なく使えますか? それとも、他の機能にも問題がありますか?
設定項目のどこか(特に「補助出力」タブ内のフリースペース等)に、以下のようなWAF(Web Application Firewall)によってブロックされやすい文字列を書いていないでしょうか?
※WAFが原因の場合は(サーバ側で拒否されてしまうので)プログラム側ではどうしようもありませんから、上記のような記述を避ける以外に対処法がありません。
🍘Re:5820◆設定の保存以外の機能は問題なく使えますか? それとも、他の機能にも問題がありますか?
設定項目のどこか(特に「補助出力」タブ内のフリースペース等)に、以下のようなWAF(Web Application Firewall)によってブロックされやすい文字列を書いていないでしょうか?
- ../../ のような上位階層を参照する文字列
- /etc/xxxx のようなシステムディレクトリを参照しようとしているっぽい文字列
※WAFが原因の場合は(サーバ側で拒否されてしまうので)プログラム側ではどうしようもありませんから、上記のような記述を避ける以外に対処法がありません。
瓦煎餅食べたいな……。
🍘Re:5814◆確かに、そのサイトだと 403 Forbidden になりますね。PHPプログラムからのアクセスだと認識して「403 Forbidden」を返しているのだと思います。この場合は残念ながらどうしようもありません。
カード型リンクは(閲覧者がブラウザでアクセスしたことをトリガーにはするのですが)、実際にはサーバ上のPHPプログラムが相手先のWebサーバへOGP情報を取りに行っていますので(その点だけを見るとBotと変わりありませんから)、強固にBotを拒否しているサーバからは情報を取得できないことがあります。(そのサイトの場合は、SNSからのアクセスは個別に許可されているのでしょう。)
シンプルな方法で情報を取得に行っていますので、「プログラムからのアクセスだ」と判別されやすいのだと思います。もうちょっと凝れば対処可能かもしれないのですけども、(人間のアクセスがトリガーになっているとはいえ)Botを強固に拒否しているサーバから無理に情報を取ってこようとはしない方が良いのではないかと今のところは思っています。
(追記) どうしてもカード型リンクで掲載したい(手間をかけても良い)と思われる場合は、No.5817の方法を使えるようにしました。^^;(次のβ版からご使用頂けます。)
🍘Re:5814◆確かに、そのサイトだと 403 Forbidden になりますね。PHPプログラムからのアクセスだと認識して「403 Forbidden」を返しているのだと思います。この場合は残念ながらどうしようもありません。
カード型リンクは(閲覧者がブラウザでアクセスしたことをトリガーにはするのですが)、実際にはサーバ上のPHPプログラムが相手先のWebサーバへOGP情報を取りに行っていますので(その点だけを見るとBotと変わりありませんから)、強固にBotを拒否しているサーバからは情報を取得できないことがあります。(そのサイトの場合は、SNSからのアクセスは個別に許可されているのでしょう。)
シンプルな方法で情報を取得に行っていますので、「プログラムからのアクセスだ」と判別されやすいのだと思います。もうちょっと凝れば対処可能かもしれないのですけども、(人間のアクセスがトリガーになっているとはいえ)Botを強固に拒否しているサーバから無理に情報を取ってこようとはしない方が良いのではないかと今のところは思っています。
(追記) どうしてもカード型リンクで掲載したい(手間をかけても良い)と思われる場合は、No.5817の方法を使えるようにしました。^^;(次のβ版からご使用頂けます。)
以下の2点を改善した版の動作テスト。
🌸Re:5809◆ご指摘ありがとうございます。たしかにそのような動作になりますね。こちらにあるソースは修正しましたので、次のバージョンからは修正版をご使用頂けます。次のβ版公開まで、もうしばらくお待ち下さい。
- ハッシュタグの中に半角 & 記号が含まれている場合に、ハッシュタグ限定表示に出てこなくなる不具合の修正。
- カード型リンクで >>5803 のように「OGPに概要文が含まれていない」ページでも、なんとなく良い感じに情報を拾ってくるように改善。
🌸Re:5809◆ご指摘ありがとうございます。たしかにそのような動作になりますね。こちらにあるソースは修正しましたので、次のバージョンからは修正版をご使用頂けます。次のβ版公開まで、もうしばらくお待ち下さい。
通りすがりに、咲いていた桜を撮影してきました。🌸🌸🌸
🌸Re:5805◆ご要望をありがとうございます。選択した投稿を一括して特定のカテゴリに属させるような機能を作るときに、下書き化する機能等も加えるようにします。とはいえ、いつ頃そういう機能が作れるかは今のところ分かりませんので、現時点で複数の記事を(たぶん)手っ取り早く下書き化する方法も書いておきます。例えば以下のような方法があります。
🌸Re:5805◆ご要望をありがとうございます。選択した投稿を一括して特定のカテゴリに属させるような機能を作るときに、下書き化する機能等も加えるようにします。とはいえ、いつ頃そういう機能が作れるかは今のところ分かりませんので、現時点で複数の記事を(たぶん)手っ取り早く下書き化する方法も書いておきます。例えば以下のような方法があります。
- データファイル tegalog.xml をダウンロードして、テキストエディタで開きます。
- 下書きにしたい投稿を探します。
- 見つかったら、その行にある <flag></flag> の記述を <flag>draft</flag> に書き換えます。(タグの中に draft という文字列を挿入するだけです。もし既に別の文字列が入っている場合は半角カンマ記号で区切って書いて下さい。)
- 必要なだけ2~3を繰り返します。
- 最後に保存して、上書きアップロードします。
4月になりましたねえ。🌸🍡🍵🌸🍡🍵🌸🍡🍵
🍵Re:5803◆そのサイトのソースを見てみたところ、OGPにタイトルはあるものの概要文がないんですよね。og:titleはあるけど、og:descriptionがない。で、概要文の取得ができなかった場合には代わりに「body要素の先頭からタグ以外の150文字を取得する」という仕様を加えたんですが、そのサイトはbody要素の先頭にscript要素を使ってJavaScriptソースが書かれているので(^_^;)、そのソースが表示されてしまっているようです。(従来のバージョンでは、概要文が取得できなかったら空欄のままになっていたので、こうはならなかったわけです。)
タグを除外する仕様は設けていたものの、そういえばスクリプトのソースはタグの外にあるのだという点を考慮していませんでした。^^;
次のバージョンでは、script要素は全体を無視するように改善します。
ご報告をありがとうございます。
🍵Re:5803◆そのサイトのソースを見てみたところ、OGPにタイトルはあるものの概要文がないんですよね。og:titleはあるけど、og:descriptionがない。で、概要文の取得ができなかった場合には代わりに「body要素の先頭からタグ以外の150文字を取得する」という仕様を加えたんですが、そのサイトはbody要素の先頭にscript要素を使ってJavaScriptソースが書かれているので(^_^;)、そのソースが表示されてしまっているようです。(従来のバージョンでは、概要文が取得できなかったら空欄のままになっていたので、こうはならなかったわけです。)
タグを除外する仕様は設けていたものの、そういえばスクリプトのソースはタグの外にあるのだという点を考慮していませんでした。^^;
次のバージョンでは、script要素は全体を無視するように改善します。
ご報告をありがとうございます。
もしかして、3月は今日で終わり……?
🍡Re:5797◆開発放言に反応ありがとうございます。^^
🍡Re:5798◆もしデータファイル(tegalog.xml)をテキストエディタで編集しても構わない場合で、そのテキストエディタで正規表現が使える場合は、以下のような感じにすることで、一括して全投稿の2行目に空行を増やせます。(図はEmEditor)

最初のbrタグを増やす正規表現
ここで処理しているのは、『<comment>タグの後に登場する、1つ目の<br />を、<br /><br />に置き換える』という内容です。これによって、1行目の直後に空行が増えます。もちろん、何行でも必要なだけ増やせます。
データファイルを直接は編集しない方法で空行を増やすのは(かかる手間の面で)難しいと思います。
🍡Re:5797◆開発放言に反応ありがとうございます。^^
🍡Re:5798◆もしデータファイル(tegalog.xml)をテキストエディタで編集しても構わない場合で、そのテキストエディタで正規表現が使える場合は、以下のような感じにすることで、一括して全投稿の2行目に空行を増やせます。(図はEmEditor)
ここで処理しているのは、『<comment>タグの後に登場する、1つ目の<br />を、<br /><br />に置き換える』という内容です。これによって、1行目の直後に空行が増えます。もちろん、何行でも必要なだけ増やせます。
データファイルを直接は編集しない方法で空行を増やすのは(かかる手間の面で)難しいと思います。
花粉飛びすぎ……。(>_<) 🌲🌳🌲🌳🌲🌳
🍘Re:5792◆ご活用をありがとうございます。以下、2つのご質問に回答します。
① 今のところ「カテゴリなし」と「何らかのカテゴリ」とを同時に表示させる方法がありません。現状の仕様では、例えば「nashi」というカテゴリを作成して、「カテゴリなし」をすべてそのカテゴリに属させた上で、cat=hobby,nashi として頂くほかありません。
なお、「カテゴリなし」の投稿をすべて特定のカテゴリに属させるには、データファイル(tegalog.xml)をテキストエディタで開いて、<cat></cat>という記述を一括して<cat>nashi</cat>に変えると楽です。
② カスタマイズ可能です。
詳しい方法は、ヘルプドキュメントの「カスタマイズ方法」ページにある『状況に応じた見出し行の装飾方法』区画をご覧下さい。
➡てがろぐ側の設定画面でも表記を選択したり書き換えたりできますし、➡CSSで装飾を調整することもできます。これらのclass名をJavaScriptで使えばもっと複雑なカスタマイズもできそうな気がします。
🍘Re:5792◆ご活用をありがとうございます。以下、2つのご質問に回答します。
① 今のところ「カテゴリなし」と「何らかのカテゴリ」とを同時に表示させる方法がありません。現状の仕様では、例えば「nashi」というカテゴリを作成して、「カテゴリなし」をすべてそのカテゴリに属させた上で、cat=hobby,nashi として頂くほかありません。
なお、「カテゴリなし」の投稿をすべて特定のカテゴリに属させるには、データファイル(tegalog.xml)をテキストエディタで開いて、<cat></cat>という記述を一括して<cat>nashi</cat>に変えると楽です。
② カスタマイズ可能です。
詳しい方法は、ヘルプドキュメントの「カスタマイズ方法」ページにある『状況に応じた見出し行の装飾方法』区画をご覧下さい。
➡てがろぐ側の設定画面でも表記を選択したり書き換えたりできますし、➡CSSで装飾を調整することもできます。これらのclass名をJavaScriptで使えばもっと複雑なカスタマイズもできそうな気がします。

1つの共通記法(共通ボタン)で外部サービス諸々を埋め込めるようになった Ver 4.7.7β(未配布)の動作テスト。
シュークリームフラペチーノ、めちゃくちゃ美味いです😋
🍮Re:5785◆今のところその方法はありません。基本的には「ログインするのは管理画面にアクセスするため」という前提の設計になっていますので。
シュークリームフラペチーノ、めちゃくちゃ美味いです😋
(ツイート埋め込み処理中...)Twitterで見る
(ツイート埋め込み処理中...)Twitterで見る
🍮Re:5785◆今のところその方法はありません。基本的には「ログインするのは管理画面にアクセスするため」という前提の設計になっていますので。
最近、団子を食べる機会がないな……。🍡🍡🍡
🍡Re:5781◆どこの何が文字化けしているかに依ります。
また、以下もご確認下さい。
なお、アップロード時に使用したFTPソフトの設定で、文字コードを自動変換してしまっていないかも確認してみて下さい。
🍡Re:5781◆どこの何が文字化けしているかに依ります。
- てがろぐが生成するページ全体が文字化けしていて読める文字が1つもない。
- てがろぐ投稿本文だけが文字化けしていて、それ以外の文字は正常。
- てがろぐ投稿本文は正常に読めるが、その周囲が文字化けしている。
また、以下もご確認下さい。
- てがろぐそのもののログイン画面なども文字化けしているのでしょうか? それとも、そこは正常に読めるのですか?
- 他のブラウザで閲覧しても結果は同じですか?
なお、アップロード時に使用したFTPソフトの設定で、文字コードを自動変換してしまっていないかも確認してみて下さい。
キットカットを食べました。🍫🍫🍫
🍫Re:5775◆回答の前に補足というか訂正というか注釈ですけども、[[HASHTAG:LIST:GALLERY]] の記法は、ハッシュタグリストをギャラリーモードへのリンクにするだけであって、「画像付記事だけのタグを出力」するわけではありません。ハッシュタグリストには全部のハッシュタグがリストアップされます。ギャラリーモードで表示される投稿が1つもないハッシュタグがあれば、移動先は「表示できる投稿がありません」等のメッセージが表示されるだけのページになります。
さて、ハッシュタグリストのリンク先を特定のカテゴリにすることは、JavaScriptを使えば可能です。
No.5708に書いたJavaScriptソースを修正するだけで実現できます。例えば、カテゴリID「info」へのリンクにしたい場合は、以下のように書けば良いです。
<script>
document.querySelectorAll('a.taglink').forEach(link => {
link.href += '&cat=info';
});
</script>
要は、『すべてのハッシュタグリンクのhref属性値の末尾に&cat=infoを加えれば良い』わけですから、上記のようなJavaScriptをスキン(skin-cover.html)の末尾に書くだけで良いです。(必ず末尾に)
ただ、上記のJavaScriptだと、そのページ内に存在するすべてのハッシュタグリンク(※本文中に書かれているハッシュタリンクも含む)が対象になりますから、ハッシュタグリストだけに限定したい場合は、ハッシュタグリストを囲んでいる何らかのclass名をquerySelectorAllの引数(の先頭)に加える必要があります。例えば、<div class="hashtaglist">~</div> の内側にあるなら、querySelectorAll('.hashtaglist a.taglink') のような感じです。
🍫Re:5775◆回答の前に補足というか訂正というか注釈ですけども、[[HASHTAG:LIST:GALLERY]] の記法は、ハッシュタグリストをギャラリーモードへのリンクにするだけであって、「画像付記事だけのタグを出力」するわけではありません。ハッシュタグリストには全部のハッシュタグがリストアップされます。ギャラリーモードで表示される投稿が1つもないハッシュタグがあれば、移動先は「表示できる投稿がありません」等のメッセージが表示されるだけのページになります。
さて、ハッシュタグリストのリンク先を特定のカテゴリにすることは、JavaScriptを使えば可能です。
No.5708に書いたJavaScriptソースを修正するだけで実現できます。例えば、カテゴリID「info」へのリンクにしたい場合は、以下のように書けば良いです。
<script>
document.querySelectorAll('a.taglink').forEach(link => {
link.href += '&cat=info';
});
</script>
要は、『すべてのハッシュタグリンクのhref属性値の末尾に&cat=infoを加えれば良い』わけですから、上記のようなJavaScriptをスキン(skin-cover.html)の末尾に書くだけで良いです。(必ず末尾に)
ただ、上記のJavaScriptだと、そのページ内に存在するすべてのハッシュタグリンク(※本文中に書かれているハッシュタリンクも含む)が対象になりますから、ハッシュタグリストだけに限定したい場合は、ハッシュタグリストを囲んでいる何らかのclass名をquerySelectorAllの引数(の先頭)に加える必要があります。例えば、<div class="hashtaglist">~</div> の内側にあるなら、querySelectorAll('.hashtaglist a.taglink') のような感じです。
リンゴを食べました。🍎
🍎Re:5771◆ご指摘をありがとうございます。調べたところ、特定の応答をするサーバからは正しくデータを取得できずにエラーを吐いていましたので、TegUp側のソースを修正しました。次の(てがろぐの)β版と一緒に配布しますので、しばらくお待ち下さい。
ただ、それでも任天堂ストアからの情報は取得できませんでした。なんでかな……と思って調べたところ、JavaScriptがONの状態でアクセスしないとコンテンツが出力されない仕様でした。なので、情報が取得できないのはどうしようもなさそうです。(任天堂側が、OGP情報だけはJavaScriptの有無に関係なく出力してくれると良いのですけどもね。)
とりあえず、TegUp側で「OGP情報が取得できなかった場合はbody要素の先頭から最大150文字ほどを取得する」という感じにしてみました。
あと、リンクラベルを入力せずにリンクカード記法を使った場合で、リンク先からOGP情報が得られなかった場合に、「(Loading...)」と表示されっぱなしになる点も改善しました。次の(てがろぐの)β版からお使い頂けます。
🍎Re:5771◆ご指摘をありがとうございます。調べたところ、特定の応答をするサーバからは正しくデータを取得できずにエラーを吐いていましたので、TegUp側のソースを修正しました。次の(てがろぐの)β版と一緒に配布しますので、しばらくお待ち下さい。
ただ、それでも任天堂ストアからの情報は取得できませんでした。なんでかな……と思って調べたところ、JavaScriptがONの状態でアクセスしないとコンテンツが出力されない仕様でした。なので、情報が取得できないのはどうしようもなさそうです。(任天堂側が、OGP情報だけはJavaScriptの有無に関係なく出力してくれると良いのですけどもね。)
とりあえず、TegUp側で「OGP情報が取得できなかった場合はbody要素の先頭から最大150文字ほどを取得する」という感じにしてみました。
あと、リンクラベルを入力せずにリンクカード記法を使った場合で、リンク先からOGP情報が得られなかった場合に、「(Loading...)」と表示されっぱなしになる点も改善しました。次の(てがろぐの)β版からお使い頂けます。
パウンドケーキを食べました。おいしい。
パウンドケーキの絵文字はないけど、見た目の雰囲気は食パンが近そう……?🍞🍞🍞
もしくは、月餅か……?🥮🥮🥮
🍞Re:5763◆確かにそうですね。ハッシュタグだとは解釈しない文字列(除外文字列)をONにしている場合でも #-123456 や #-123 や #-1 のような隠れハッシュタグは除外しない(隠れハッシュタグとして認識する)ように仕様を変更しました。また、No.5762でのご指摘もありがとうございます。ちょいと処理を修正してみました。今は、No.5762では正しくリンクされていると思います。次のβ版からご使用頂けます。
🍞Re:5764◆使えるようにします~。もうしばらくお待ち下さい。
パウンドケーキの絵文字はないけど、見た目の雰囲気は食パンが近そう……?🍞🍞🍞
もしくは、月餅か……?🥮🥮🥮
🍞Re:5763◆確かにそうですね。ハッシュタグだとは解釈しない文字列(除外文字列)をONにしている場合でも #-123456 や #-123 や #-1 のような隠れハッシュタグは除外しない(隠れハッシュタグとして認識する)ように仕様を変更しました。また、No.5762でのご指摘もありがとうございます。ちょいと処理を修正してみました。今は、No.5762では正しくリンクされていると思います。次のβ版からご使用頂けます。
🍞Re:5764◆使えるようにします~。もうしばらくお待ち下さい。
買い物に行ったのに、たこ焼きのことはすっかり忘れていたので、冷凍たこ焼きを買い忘れました。
🍘Re:5752◆ああ、確かにその動作になりますね。これまでそのような動作にしてきたのは、以下の2つの理由からでした。2つ目はご推察の通りです。
下げる・下書き投稿の場合でも、投稿単独ページへ移動されるようなオプション設定も用意したいと思います。
🍘Re:5754◆iframeよりは、JavaScriptのfetchで読み込んで合成する方がデザイン自由度が高くて良いかもしれません。iframeだと、フレームの内部が1つの独立したWebページになってしまいますが、JavaScriptで合成すれば、合成した結果が1つのWebページになりますから。それに、JavaScriptだと、別途用意しておいた「カテゴリAやBの一覧ページ」から必要な部分だけを抜き出して合成することもできます。
🍘Re:5755◆リスト記法の [L: の直後で改行すれば良いです。(リストの仕様にも書いてありますが、先頭の改行はあってもなくても同じで、空行は無視されます。)そうすると、
🍘Re:5752◆ああ、確かにその動作になりますね。これまでそのような動作にしてきたのは、以下の2つの理由からでした。2つ目はご推察の通りです。
- HOMEに戻る動作が前提の仕様だったので、(下げた投稿も下書き投稿もHOMEには表示されないので)HOMEに戻ってしまうと「いま投稿したばかりの投稿が見えない」という状況になってしまって困惑を招くかもしれないので強制的にステータス画面を出す方が分かりやすいだろうから。
- 下げた投稿や下書き投稿に関する案内を見せるため。
下げる・下書き投稿の場合でも、投稿単独ページへ移動されるようなオプション設定も用意したいと思います。
🍘Re:5754◆iframeよりは、JavaScriptのfetchで読み込んで合成する方がデザイン自由度が高くて良いかもしれません。iframeだと、フレームの内部が1つの独立したWebページになってしまいますが、JavaScriptで合成すれば、合成した結果が1つのWebページになりますから。それに、JavaScriptだと、別途用意しておいた「カテゴリAやBの一覧ページ」から必要な部分だけを抜き出して合成することもできます。
🍘Re:5755◆リスト記法の [L: の直後で改行すれば良いです。(リストの仕様にも書いてありますが、先頭の改行はあってもなくても同じで、空行は無視されます。)そうすると、
- 1:20 さくらたん
- 5:35 ともよちゃん
最近、クロワッサンを食べていないな……。🥐🥐🥐
🥐Re:5749◆カテゴリの一覧を出すだけなら、現状のカテゴリツリーがまさしくそういう構造だと思いますが、それでは何が不足ですか?
カテゴリそのものの一覧ではなく、『「カテゴリに属している投稿の一覧」をカテゴリ別に出したい』ということでしょうかね?
その場合、カテゴリIDを手動で指定して良いのであれば、「新着投稿リストの掲載対象をスキン側で限定する方法(掲載する対象を選択)」で解説している方法があります。これでも不足する場合は、どんな機能が不足しているのかをご指摘頂けると、新機能を検討する参考になってありがたいです。
なお、ここで過去にちょっとだけ出てきた「カテゴリ目次モード」という案もあります。(これもできたら良いな……とは思うのですけども、スキンをどんな仕様にしたらいいかな……という点でちょっと迷っています。スキン側には特別な書き方は用意せず、「日付境界バー」のような感じで「カテゴリ名を出す」という感じでも良いのかもしれませんが。)
🥐Re:5750◆編集画面に任意のスクリプト等を挿入する方法には、以下の2通りがあります。
したがって、おっしゃる「skin=hogeなどが付いていてもedit.jsなどを反映させるように」は既になっています。動作を再確認してみて下さい。(もしそれでも反映されていないように見える場合は、どのようにファイルを置いて、何を見た結果「反映されていない」と判断したのかを教えて頂けると、何らかの回答ができるかもしれません。)
🥐Re:5749◆カテゴリの一覧を出すだけなら、現状のカテゴリツリーがまさしくそういう構造だと思いますが、それでは何が不足ですか?
カテゴリそのものの一覧ではなく、『「カテゴリに属している投稿の一覧」をカテゴリ別に出したい』ということでしょうかね?
その場合、カテゴリIDを手動で指定して良いのであれば、「新着投稿リストの掲載対象をスキン側で限定する方法(掲載する対象を選択)」で解説している方法があります。これでも不足する場合は、どんな機能が不足しているのかをご指摘頂けると、新機能を検討する参考になってありがたいです。
なお、ここで過去にちょっとだけ出てきた「カテゴリ目次モード」という案もあります。(これもできたら良いな……とは思うのですけども、スキンをどんな仕様にしたらいいかな……という点でちょっと迷っています。スキン側には特別な書き方は用意せず、「日付境界バー」のような感じで「カテゴリ名を出す」という感じでも良いのかもしれませんが。)
🥐Re:5750◆編集画面に任意のスクリプト等を挿入する方法には、以下の2通りがあります。
- edit.jsとedit.cssは、パラメータにスキンが指定された ?skin=skin-journal&mode=edit のようなURLでも読み込まれます。常に、CGI本体と同じディレクトリにあるファイルが読み込まれる仕様ですから。(スキンに関係なく挿入されます。)
- edit.htmの場合は、適用中のスキンディレクトリにあるファイルだけが読み込まれる仕様なので、適用スキンを切り替えると(適用先のスキンディレクトリにedit.htmがなければ)読み込まれません。(スキン別に挿入ファイルを用意できるようにするためです。)
したがって、おっしゃる「skin=hogeなどが付いていてもedit.jsなどを反映させるように」は既になっています。動作を再確認してみて下さい。(もしそれでも反映されていないように見える場合は、どのようにファイルを置いて、何を見た結果「反映されていない」と判断したのかを教えて頂けると、何らかの回答ができるかもしれません。)
昼食はスパゲッティでした。🍝
🍝Re:5740◆おぉ、情報ありがとうございます。一覧がありがたいです。こんなに使われているシステムなんですねえ。デファクトスタンダードになりそうな……? おもしろそうなので、埋め込み対応する方向で考えてみます。気長にお待ち頂ければ幸いです。
🍝Re:5740◆おぉ、情報ありがとうございます。一覧がありがたいです。こんなに使われているシステムなんですねえ。デファクトスタンダードになりそうな……? おもしろそうなので、埋め込み対応する方向で考えてみます。気長にお待ち頂ければ幸いです。
夕食に、おでんを食べておなかいっぱい。ぐっふぅ。_(:3」∠)_
🍢Re:5735◆なるほど、あの手のWeb漫画も埋め込み機能があったんですねえ。少年ジャンプ+とコミックデイズを見てみると、かなりシンプルな埋め込みURLで埋め込める仕様ですね。(無料公開が終わってしまったらどんな表示になるのかがちょっと分かりませんけども。)需要次第な面もありますがちょっと考えます。少年ジャンプ+とコミックデイズ以外でも使われていそうな感じですね? もしかしてWebコミックでは割と広く使われているのかな……?
🍢Re:5736◆表示に使うスクリプトの仕様次第で方法は様々ですからざっくりした話しかできませんが、例えば、
カテゴリで使用スクリプトを分けられるのであれば、「投稿本文を囲む外側の要素」に「カテゴリIDがclass名に入る」ようにスキンを書いておけば、投稿本文側には何の工夫も要らなくできますけども。
例えば、投稿本文が <div class="comment">~</div> で囲まれているなら、<div class="comment [[CATEGORYIDS]]">~</div> のように書く感じで。カテゴリIDを加える記法については、リファレンスの【カテゴリ関連要素】もご覧下さい。
🍢Re:5735◆なるほど、あの手のWeb漫画も埋め込み機能があったんですねえ。少年ジャンプ+とコミックデイズを見てみると、かなりシンプルな埋め込みURLで埋め込める仕様ですね。(無料公開が終わってしまったらどんな表示になるのかがちょっと分かりませんけども。)需要次第な面もありますがちょっと考えます。少年ジャンプ+とコミックデイズ以外でも使われていそうな感じですね? もしかしてWebコミックでは割と広く使われているのかな……?
🍢Re:5736◆表示に使うスクリプトの仕様次第で方法は様々ですからざっくりした話しかできませんが、例えば、
- まんが [F:manga:[PICT:manga.png]]
- イラスト [F:illust:[PICT:illust.jpg]]
- まんが用の拡大スクリプトは .uc-manga .embeddedimage を対象に
- イラスト用拡大スクリプトは .uc-illust .embeddedimage を対象に
カテゴリで使用スクリプトを分けられるのであれば、「投稿本文を囲む外側の要素」に「カテゴリIDがclass名に入る」ようにスキンを書いておけば、投稿本文側には何の工夫も要らなくできますけども。
例えば、投稿本文が <div class="comment">~</div> で囲まれているなら、<div class="comment [[CATEGORYIDS]]">~</div> のように書く感じで。カテゴリIDを加える記法については、リファレンスの【カテゴリ関連要素】もご覧下さい。
微かに喉が痛いので、龍角散のど飴をなめていました。🍬🍬🍬
ただし、賞味期限は2025年1月。┌(:3」└)┐ >>4991
🍬Re:5725◆URLの中に & 記号をそのままを書くと、それはパラメータの区切りであると認識されてしまいます。「&以降の文字がTwitter側で表示されない」という現象の原因はそれです。
▼背景:
例えば、Web上のシステムに何らかのパラメータを送る場合、
https://example.com/?url=AAA&title=BBB&text=CCC&name=DDD
のような感じで「パラメータ=値」のセットを「 & 」で連結しますよね。上記の場合は、
もしここで、「BBB」の部分を「Baa&Bee」のように「 & 」記号を含む形で書いてしまうと、
https://example.com/?url=AAA&title=Baa&Bee&text=CCC&name=DDD
これは以下のように、
半角の「 & 」記号があれば常にパラメータの区切りになるからです。
本当は「Baa&Bee」というタイトルなのに「&」がパラメータの区切りだと認識されるため、タイトルの認識範囲は「Baa」で終わってしまうわけですね。「&に続くその先の文字がTwitterでタイトルとして認識されない」のもこのためです。
(※ここでは & を文字実体参照にして Baa&Bee としていても同じことで、やはりこの & は区切りになります。)
▼対処方法:
URLの中に「 & 」記号そのものを文字として含めたい場合には、URLエンコードという規則に従って & 1文字を %26 という3文字に置き換える必要があります。
先の例だと、
https://example.com/?url=AAA&title=Baa%26Bee&text=CCC&name=DDD
……のようにします。そうすれば、「Baa%26Bee」が「Baa&Bee」にデコード(復元)されて、
このような変換はJavaScript側でするしかありませんから(JavaScriptにはそのための関数 encodeURIComponent が用意されています)、てがろぐ側の本文([[COMMENT:TITLE]]等)を取得してURLエンコードしてから「Twitterへ送るURL」を生成するようなJavaScriptを用意する必要があるでしょう。
※なお、<![CDATA[で始まり]]>で終わるCDATA(読みはたぶんシー・データ)はXMLでの特別な書き方なので、HTMLには無関係です。畳む
ただし、賞味期限は2025年1月。┌(:3」└)┐ >>4991
🍬Re:5725◆URLの中に & 記号をそのままを書くと、それはパラメータの区切りであると認識されてしまいます。「&以降の文字がTwitter側で表示されない」という現象の原因はそれです。
▼背景:
例えば、Web上のシステムに何らかのパラメータを送る場合、
https://example.com/?url=AAA&title=BBB&text=CCC&name=DDD
のような感じで「パラメータ=値」のセットを「 & 」で連結しますよね。上記の場合は、
- urlパラメータの値がAAA
- titleパラメータの値がBBB
- textパラメータの値がCCC
- nameパラメータの値がDDD
もしここで、「BBB」の部分を「Baa&Bee」のように「 & 」記号を含む形で書いてしまうと、
https://example.com/?url=AAA&title=Baa&Bee&text=CCC&name=DDD
これは以下のように、
- urlパラメータの値がAAA
- titleパラメータの値がBaa (←&記号の直前まで)
- Beeパラメータ(値なし) (←&記号の直後から)
- textパラメータの値がCCC
- nameパラメータの値がDDD
半角の「 & 」記号があれば常にパラメータの区切りになるからです。
本当は「Baa&Bee」というタイトルなのに「&」がパラメータの区切りだと認識されるため、タイトルの認識範囲は「Baa」で終わってしまうわけですね。「&に続くその先の文字がTwitterでタイトルとして認識されない」のもこのためです。
(※ここでは & を文字実体参照にして Baa&Bee としていても同じことで、やはりこの & は区切りになります。)
▼対処方法:
URLの中に「 & 」記号そのものを文字として含めたい場合には、URLエンコードという規則に従って & 1文字を %26 という3文字に置き換える必要があります。
先の例だと、
https://example.com/?url=AAA&title=Baa%26Bee&text=CCC&name=DDD
……のようにします。そうすれば、「Baa%26Bee」が「Baa&Bee」にデコード(復元)されて、
- titleパラメータの値はBaa&Bee
このような変換はJavaScript側でするしかありませんから(JavaScriptにはそのための関数 encodeURIComponent が用意されています)、てがろぐ側の本文([[COMMENT:TITLE]]等)を取得してURLエンコードしてから「Twitterへ送るURL」を生成するようなJavaScriptを用意する必要があるでしょう。
※なお、<![CDATA[で始まり]]>で終わるCDATA(読みはたぶんシー・データ)はXMLでの特別な書き方なので、HTMLには無関係です。畳む
>5724
にししさん、返信ありがとうございます。5720です。
RSSが表示できない問題に関してですが、どうやらCDDATAの記載を必要ないと思って無知ゆえに消していたらしく、記載したらRSSが取得できるようになりました。不具合だというのは私の勘違いで失礼いたしました。
ところで、最近話題になっていたTwitterでの記事共有ボタンの実装を行ったのですが、タイトルに&を書いてしまうと、&に続くその先の文字が表示されないことがありました。
これもCDDATAがないことが原因だったりするんでしょうか。
<a href="https://twitter.com/intent/tweet?url=[[PERMAURL:PURE:FULL]]&text=CDATA[[COMMENT:TITLE]]%0aサイト名%0a" title="ツイッターに投稿" target="_blank" rel="noopener" class="share"
にししさん、返信ありがとうございます。5720です。
RSSが表示できない問題に関してですが、どうやらCDDATAの記載を必要ないと思って無知ゆえに消していたらしく、記載したらRSSが取得できるようになりました。不具合だというのは私の勘違いで失礼いたしました。
ところで、最近話題になっていたTwitterでの記事共有ボタンの実装を行ったのですが、タイトルに&を書いてしまうと、&に続くその先の文字が表示されないことがありました。
これもCDDATAがないことが原因だったりするんでしょうか。
<a href="https://twitter.com/intent/tweet?url=[[PERMAURL:PURE:FULL]]&text=CDATA[[COMMENT:TITLE]]%0aサイト名%0a" title="ツイッターに投稿" target="_blank" rel="noopener" class="share"
朝食はホットドッグ。🌭🌭🌭
🌭Re:5723◆ああ、なるほど。
<script>
document.querySelectorAll('a.uc-normallink').forEach(link => {
link.removeAttribute('target');
});
</script>
もちろんclass名は何でも自由に付ければ良いです。(※JavaScript側では、投稿本文中に書いたclass名の頭に uc- という接頭辞が付く点にご注意下さい。詳しくは リンクに任意のclass属性値を加える記法 の囲み部分をご覧下さい。)
なお、ここでのremoveAttribute('target')というのが、target属性を削除するという処理です。(a要素からtarget属性を削除すれば、リンクは常に同一タブで開かれるようになります。)
対象のリンクが全体の1%くらいしかないのであれば、上記のような対処法でもそこまで面倒ではないのではないかと思います。とはいえ、てがろぐ側の記法として「リンク先ウインドウを同一にする」というオプションも用意しておくと良さそうですね。需要がどれくらいあるのかは分かっていませんが、ToDoリストに入れておきます。
🌭Re:5723◆ああ、なるほど。
- もしデフォルト設定が「同一ウインドウ(タブ)で開く」なのであれば、特定のリンクだけを「リンク先は新規ウインドウ(タブ)で開く」にする記法はありますが、
- その逆で、デフォルトの方が「リンク先は新規ウインドウ(タブ)で開く」の設定になっているときに、特定のリンクだけを「同一ウインドウ(タブ)で開く」ようにする方法は(てがろぐ側の機能としては)ありませんね。
- 同一タブで開きたいリンクは、リンクに任意のclass属性値を加える記法「 :CL(英数字) 」を使って、 [リンクラベル:CL(normallink)]https://任意のURL のように書く
<script>
document.querySelectorAll('a.uc-normallink').forEach(link => {
link.removeAttribute('target');
});
</script>
もちろんclass名は何でも自由に付ければ良いです。(※JavaScript側では、投稿本文中に書いたclass名の頭に uc- という接頭辞が付く点にご注意下さい。詳しくは リンクに任意のclass属性値を加える記法 の囲み部分をご覧下さい。)
なお、ここでのremoveAttribute('target')というのが、target属性を削除するという処理です。(a要素からtarget属性を削除すれば、リンクは常に同一タブで開かれるようになります。)
対象のリンクが全体の1%くらいしかないのであれば、上記のような対処法でもそこまで面倒ではないのではないかと思います。とはいえ、てがろぐ側の記法として「リンク先ウインドウを同一にする」というオプションも用意しておくと良さそうですね。需要がどれくらいあるのかは分かっていませんが、ToDoリストに入れておきます。
見かけたからには買わずにはいられなかったお茶。
🍵Re:5716◆個人サイト頑張って下さい~。
🍵Re:5717◆解説ありがとうございます!
🍵Re:5718◆なるほど、削除動画。そんなのがあるんですね。これなら確かに問題なさそうですね。^^;
🍵Re:5719◆余裕で設置できて良かったです~。
🍵Re:5720◆自作のRSS用スキンをお使いでしょうか?
その場合、スキン内のtitle要素を <title><![CDATA[ 中身 ]]></title> ではなく <title>中身</title> と書いてしまっていませんか?(そのほかdescriptionなど、投稿内容(一部分でも)を出力する箇所はすべて <![CDATA[ ~ ]]> で囲む必要があります。)
標準添付のRSS用スキンのソースもご参照下さい。CDATAの意味はいろんなところに解説がありますが、例えば「XMLのCDATAとは」などをご覧頂くと良い気がします。
🍵Re:5716◆個人サイト頑張って下さい~。
🍵Re:5717◆解説ありがとうございます!
🍵Re:5718◆なるほど、削除動画。そんなのがあるんですね。これなら確かに問題なさそうですね。^^;
🍵Re:5719◆余裕で設置できて良かったです~。
🍵Re:5720◆自作のRSS用スキンをお使いでしょうか?
その場合、スキン内のtitle要素を <title><![CDATA[ 中身 ]]></title> ではなく <title>中身</title> と書いてしまっていませんか?(そのほかdescriptionなど、投稿内容(一部分でも)を出力する箇所はすべて <![CDATA[ ~ ]]> で囲む必要があります。)
標準添付のRSS用スキンのソースもご参照下さい。CDATAの意味はいろんなところに解説がありますが、例えば「XMLのCDATAとは」などをご覧頂くと良い気がします。
節分なので豆を食べました。鰯と恵方巻きも食べました。恵方がどっちなのかは認識していませんけども。┌(:3」└)┐
🍣Re:5710◆早速β版のご試用をありがとうございます。お役に立って良かったです~。(╹◡╹)ノ 他の機能の感想もありがとうございます。
🍣Re:5711◆一部分だけのリンク先をカスタマイズしたい場合はJavaScriptが便利ですね。
🍣Re:5712◆解説ページを参照して下さってありがとうございます。書いた甲斐があったというものです。(╹◡╹)
🍣Re:5713◆追加解説ありがとうございます。背景事情はよく分かりました。
カテゴリの動作に関してですが、実装が複雑になるとバグが出やすくなる問題がありますから、(将来的に何かものすごく良い感じに解決できるスマートな実装方法を思いついた場合には実装する可能性もありますが)今のところは「もう1個てがろぐを設置する」というシンプルな解決法の採用が公式のお勧めと思って下さい。(^_^;) TegUpをゼロクリックで実行できる設定を用意することで、アップデート時の「1クリック」の手間を削減する機能は作りたいと思っています。
◆投稿ボタン:なるほど、既に文字数をカウントする処理を入れているので、そのついでに「0だったら(かつ画像UPがなければ)disabledにする」という処理を加えられる選択肢を用意しても良さそうですね。ちょっと考えます。
◆投稿エリア:用途の解説をありがとうございます。理解できました。JavaScriptでEnterキーの押下を無効にすることで改行の入力を防ぐことは可能ですが、日本語入力の確定に使う[Enter]を阻止すると困るでしょうから、そこを除外する処理がちょっと面倒そうですね。全く動作確認をしていないんですが、もしかしたら以下のようなJavaScriptで(日本語入力時以外での)Enterの押下を無効化できるかもしれません。
<script>
document.querySelectorAll('textarea.tegalogpost').forEach(el => {
el.addEventListener('keydown', e => {
if(e.key === 'Enter' && !e.ctrlKey && !e.isComposing) {
e.preventDefault();
}
});
});
</script>
※QUICKPOSTが複数ある場合でも大丈夫です。スキン skin-cover.html で、すべてのQUICKPOSTが出力され切った後(末尾付近など)の位置に書いて下さい。
Ctrlキーの押下時も除外しないように書いていますが、これは [Ctrl]+[Enter]での送信機能を阻害してしまわないようにするためです。(たぶんインラインのonkeydownイベントの方が先に実行される気がするので、考慮しなくても阻害はされない気もするんですが、まあ念のために。)畳む
※なお、input要素で投稿欄を作ると、改行は入力されませんが、その代わりにEnterキーを押すだけでフォーム内容が送信されてしまう気がします。たぶん。(画像管理画面で画像のキャプションを書く欄等にカーソルがある状態でEnterキーを押すと送信されるように。^^;)
🍣Re:5714◆ご返答ありがとうございます。①についてはToDoリストに入れておきます。いつ頃できるかは分かりませんが、気長にお待ち頂ければ幸いです。
β版のご試用もありがとうございます。「直近画像の選択」で挿入される記法を「キャプションなし」にする設定は既に用意してありますので、下図の水色矢印部分で設定して下さい。

挿入される画像表示記法の選択
ここで「キャプションなし」の方にして保存すれば、常に FIG が付かない [PICT:~] 記法で挿入されます。
🍣Re:5710◆早速β版のご試用をありがとうございます。お役に立って良かったです~。(╹◡╹)ノ 他の機能の感想もありがとうございます。
🍣Re:5711◆一部分だけのリンク先をカスタマイズしたい場合はJavaScriptが便利ですね。
🍣Re:5712◆解説ページを参照して下さってありがとうございます。書いた甲斐があったというものです。(╹◡╹)
🍣Re:5713◆追加解説ありがとうございます。背景事情はよく分かりました。
カテゴリの動作に関してですが、実装が複雑になるとバグが出やすくなる問題がありますから、(将来的に何かものすごく良い感じに解決できるスマートな実装方法を思いついた場合には実装する可能性もありますが)今のところは「もう1個てがろぐを設置する」というシンプルな解決法の採用が公式のお勧めと思って下さい。(^_^;) TegUpをゼロクリックで実行できる設定を用意することで、アップデート時の「1クリック」の手間を削減する機能は作りたいと思っています。
◆投稿ボタン:なるほど、既に文字数をカウントする処理を入れているので、そのついでに「0だったら(かつ画像UPがなければ)disabledにする」という処理を加えられる選択肢を用意しても良さそうですね。ちょっと考えます。
◆投稿エリア:用途の解説をありがとうございます。理解できました。JavaScriptでEnterキーの押下を無効にすることで改行の入力を防ぐことは可能ですが、日本語入力の確定に使う[Enter]を阻止すると困るでしょうから、そこを除外する処理がちょっと面倒そうですね。全く動作確認をしていないんですが、もしかしたら以下のようなJavaScriptで(日本語入力時以外での)Enterの押下を無効化できるかもしれません。
<script>
document.querySelectorAll('textarea.tegalogpost').forEach(el => {
el.addEventListener('keydown', e => {
if(e.key === 'Enter' && !e.ctrlKey && !e.isComposing) {
e.preventDefault();
}
});
});
</script>
※QUICKPOSTが複数ある場合でも大丈夫です。スキン skin-cover.html で、すべてのQUICKPOSTが出力され切った後(末尾付近など)の位置に書いて下さい。
Ctrlキーの押下時も除外しないように書いていますが、これは [Ctrl]+[Enter]での送信機能を阻害してしまわないようにするためです。(たぶんインラインのonkeydownイベントの方が先に実行される気がするので、考慮しなくても阻害はされない気もするんですが、まあ念のために。)畳む
※なお、input要素で投稿欄を作ると、改行は入力されませんが、その代わりにEnterキーを押すだけでフォーム内容が送信されてしまう気がします。たぶん。(画像管理画面で画像のキャプションを書く欄等にカーソルがある状態でEnterキーを押すと送信されるように。^^;)
🍣Re:5714◆ご返答ありがとうございます。①についてはToDoリストに入れておきます。いつ頃できるかは分かりませんが、気長にお待ち頂ければ幸いです。
β版のご試用もありがとうございます。「直近画像の選択」で挿入される記法を「キャプションなし」にする設定は既に用意してありますので、下図の水色矢印部分で設定して下さい。
ここで「キャプションなし」の方にして保存すれば、常に FIG が付かない [PICT:~] 記法で挿入されます。
昼食はチーズを載せたパンとピザ。🧀🍞🍕🧀🍞🍕🧀🍞🍕
🍞Re:5705◆本文中のハッシュタグリンクすべてを「サイトマップモードで表示されるリンクに変えたい」のですね。それはチョー簡単です。今すぐできます。要は、『すべてのハッシュタグリンクのhref属性値の末尾に&mode=sitemapを加えれば良い』わけですから、以下のようなJavaScriptをスキン(skin-cover.html)の末尾に書くだけで良いです。(必ず末尾に)
<script>
document.querySelectorAll('a.taglink').forEach(link => {
link.href += '&mode=sitemap';
});
</script>
めちゃくちゃ簡単💛
お試し下さい。
なお、上記のJavaScriptだと、そのページ内に存在するすべてのハッシュタグリンク(※サイトバー等に表示するハッシュタグリストも含む)が対象になります。もし、本文中にあるハッシュタグリンクだけに限定したい場合は、本文を囲んでいる何らかのclass名をquerySelectorAllの引数(の先頭)に加えると良いです。例えば、本文が <div class="comment">~</div> の内側にあるのだとすれば、querySelectorAll('.comment a.taglink') のような感じです。
🍞Re:5706◆今月は28日までしかないので気を付けないと……!
🍞Re:5707◆β版のご試用をありがとうございます。役に立ったようで良かったです。(╹◡╹)ノ
ご要望もありがとうございます。
◆前者:汎用装飾記法でclass入力ダイアログを出さずに済ませる設定は確かにあると便利そうですね。ちょっと考えます。
※色指定等の入力ダイアログはJavaScriptの標準的な機能で出力していますので、これが動作しないならそれはブラウザ側の問題ですから、ブラウザの設定を見直してみて下さい。なお、文字色や背景色の記法を「色名の入力を省略した状態」で挿入したい場合は、代わりに「何でも簡単入力ボタン機能」をお使い頂くと良いと思います。
◆中者:過去の画像を複数個まとめてアップロードする場合は、画像ファイルの元々のタイムスタンプを維持してアップロードしてくれるFTPソフトを使うと(タイムスタンプがアップロード日時にはならずに済むので)便利です。その場合、てがろぐ上では何もしなくても望みの順序で表示されます。例えば下図のような感じです。
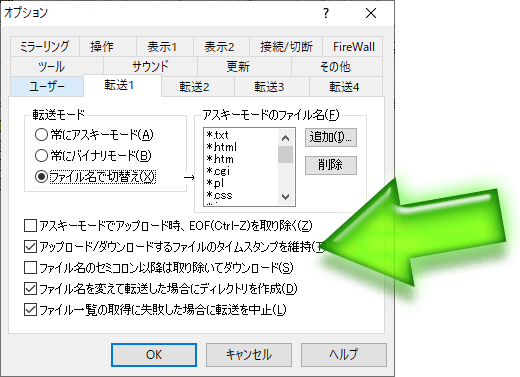
タイムスタンプを維持する設定(FFFTP)
※てがろぐ側で画像アップロード時に元のタイムスタンプを維持できないのか、と思われるかもしれませんが、HTMLの <input type="file"> を使ったアップロードでは、ファイルの中身とファイル名以外の情報は何も送られてこないので、元のタイムスタンプを知る方法がないのです。
◆後者:ああ、確かに画像を削除する方法は分かりにくい位置にしかありませんね。私も過去に「どうやって消すんだっけな」と一瞬迷うこともあったんですが、削除する頻度が極めて低かったので特に何も考えていませんでした。(^_^;) 画像1個単位でも削除できるボタン等を用意するようにします。
🍞Re:5705◆本文中のハッシュタグリンクすべてを「サイトマップモードで表示されるリンクに変えたい」のですね。それはチョー簡単です。今すぐできます。要は、『すべてのハッシュタグリンクのhref属性値の末尾に&mode=sitemapを加えれば良い』わけですから、以下のようなJavaScriptをスキン(skin-cover.html)の末尾に書くだけで良いです。(必ず末尾に)
<script>
document.querySelectorAll('a.taglink').forEach(link => {
link.href += '&mode=sitemap';
});
</script>
めちゃくちゃ簡単💛
お試し下さい。
なお、上記のJavaScriptだと、そのページ内に存在するすべてのハッシュタグリンク(※サイトバー等に表示するハッシュタグリストも含む)が対象になります。もし、本文中にあるハッシュタグリンクだけに限定したい場合は、本文を囲んでいる何らかのclass名をquerySelectorAllの引数(の先頭)に加えると良いです。例えば、本文が <div class="comment">~</div> の内側にあるのだとすれば、querySelectorAll('.comment a.taglink') のような感じです。
🍞Re:5706◆今月は28日までしかないので気を付けないと……!
🍞Re:5707◆β版のご試用をありがとうございます。役に立ったようで良かったです。(╹◡╹)ノ
ご要望もありがとうございます。
◆前者:汎用装飾記法でclass入力ダイアログを出さずに済ませる設定は確かにあると便利そうですね。ちょっと考えます。
※色指定等の入力ダイアログはJavaScriptの標準的な機能で出力していますので、これが動作しないならそれはブラウザ側の問題ですから、ブラウザの設定を見直してみて下さい。なお、文字色や背景色の記法を「色名の入力を省略した状態」で挿入したい場合は、代わりに「何でも簡単入力ボタン機能」をお使い頂くと良いと思います。
◆中者:過去の画像を複数個まとめてアップロードする場合は、画像ファイルの元々のタイムスタンプを維持してアップロードしてくれるFTPソフトを使うと(タイムスタンプがアップロード日時にはならずに済むので)便利です。その場合、てがろぐ上では何もしなくても望みの順序で表示されます。例えば下図のような感じです。
※てがろぐ側で画像アップロード時に元のタイムスタンプを維持できないのか、と思われるかもしれませんが、HTMLの <input type="file"> を使ったアップロードでは、ファイルの中身とファイル名以外の情報は何も送られてこないので、元のタイムスタンプを知る方法がないのです。
◆後者:ああ、確かに画像を削除する方法は分かりにくい位置にしかありませんね。私も過去に「どうやって消すんだっけな」と一瞬迷うこともあったんですが、削除する頻度が極めて低かったので特に何も考えていませんでした。(^_^;) 画像1個単位でも削除できるボタン等を用意するようにします。
鉄分を補給すべくQBB鉄分ベビーチーズを食べました。🧀🧀🧀
🧀Re:5699◆クロッカンっぽい絵文字がなかったので。(笑) 少なくともWindows版では🥮が一番近そうな……?
◆次のβ版には間に合わないだろうと思っていたのですが、意外とそうでもなく簡単に加えられましたので、何でも簡単入力ボタン機能のボタンラベルの上限変更機能はVer 4.7.5βで搭載しました。ご活用頂ければ幸いです。
◆ブログ記事もお役に立ったようで嬉しいです。Bluetooth経由でモバイル端末側にグラフの形で蓄積されるのがとても便利です。
🧀Re:5700◆ご要望をありがとうございます。詳しい背景説明も分かりやすくて助かります。
◆①:なるほど、確かにカテゴリリストも該当数でフィルタリングできると便利そうですね。その場合、ツリー表示ではなく1次元のリストでも良さそうでしょうか? もし「子カテゴリの該当数も親カテゴリに参入して判定させたい」となると、今のカテゴリの仕様だと苦しいので、カテゴリそのものの管理方法を改革するまで先送りになりますが、ツリー構造を無視して「指定該当数を超えたものだけを(1次元のリストで)出す」という形なら、そう遠くないうちにできそうな気がします。(たぶん)
◆②:何らかの専用記法で特定のハッシュタグやカテゴリの該当数が取得できる仕組みを用意しておくと、いろいろ応用できそうな気もしますので、専用記法もちょっと考えてみます。
なお、これらの点については、カテゴリリストやハッシュタグ一覧が同一ページ内に出力されているのであれば(CSSで非表示にしていても可)JavaScriptでも実現可能ですから、以下の方法で今すぐにお試し頂くこともできます。
以下のような2つの関数を用意しておきます。(※ここでは、カテゴリリストをカスタマイズせず標準構造のまま出力している場合を前提にしています。)
function getTagCount(tagName) {
const links = document.querySelectorAll(".hashtaglist li");
for(const li of links) {
const a = li.querySelector('a');
const span = li.querySelector('.num');
if(a && span && a.textContent.trim() === tagName) {
return span.textContent.replace(/[()]/g, '');
}
}
return null;
}
function getCatCount(catName) {
const catTexts = document.querySelectorAll('.cattree .cattext');
for(const el of catTexts) {
if(el.textContent.trim() === catName) {
const li = el.closest('li');
const num = li.querySelector('.num');
return num ? num.textContent.replace(/[()]/g, '') : null;
}
}
return null;
}
これらの関数が使える状態で、
🧀Re:5701◆そうですね。私も時々表示確認するときに毎回気になってはいたんですが、「まあ……、いいかな……」と思って放置していました。(笑) 黒板スキンで常にご覧になっている方が居るとは予想していませんでしたので。^^; そのうちどうにかします。^^;
🧀Re:5699◆クロッカンっぽい絵文字がなかったので。(笑) 少なくともWindows版では🥮が一番近そうな……?
◆次のβ版には間に合わないだろうと思っていたのですが、意外とそうでもなく簡単に加えられましたので、何でも簡単入力ボタン機能のボタンラベルの上限変更機能はVer 4.7.5βで搭載しました。ご活用頂ければ幸いです。
◆ブログ記事もお役に立ったようで嬉しいです。Bluetooth経由でモバイル端末側にグラフの形で蓄積されるのがとても便利です。
🧀Re:5700◆ご要望をありがとうございます。詳しい背景説明も分かりやすくて助かります。
◆①:なるほど、確かにカテゴリリストも該当数でフィルタリングできると便利そうですね。その場合、ツリー表示ではなく1次元のリストでも良さそうでしょうか? もし「子カテゴリの該当数も親カテゴリに参入して判定させたい」となると、今のカテゴリの仕様だと苦しいので、カテゴリそのものの管理方法を改革するまで先送りになりますが、ツリー構造を無視して「指定該当数を超えたものだけを(1次元のリストで)出す」という形なら、そう遠くないうちにできそうな気がします。(たぶん)
◆②:何らかの専用記法で特定のハッシュタグやカテゴリの該当数が取得できる仕組みを用意しておくと、いろいろ応用できそうな気もしますので、専用記法もちょっと考えてみます。
なお、これらの点については、カテゴリリストやハッシュタグ一覧が同一ページ内に出力されているのであれば(CSSで非表示にしていても可)JavaScriptでも実現可能ですから、以下の方法で今すぐにお試し頂くこともできます。
以下のような2つの関数を用意しておきます。(※ここでは、カテゴリリストをカスタマイズせず標準構造のまま出力している場合を前提にしています。)
function getTagCount(tagName) {
const links = document.querySelectorAll(".hashtaglist li");
for(const li of links) {
const a = li.querySelector('a');
const span = li.querySelector('.num');
if(a && span && a.textContent.trim() === tagName) {
return span.textContent.replace(/[()]/g, '');
}
}
return null;
}
function getCatCount(catName) {
const catTexts = document.querySelectorAll('.cattree .cattext');
for(const el of catTexts) {
if(el.textContent.trim() === catName) {
const li = el.closest('li');
const num = li.querySelector('.num');
return num ? num.textContent.replace(/[()]/g, '') : null;
}
}
return null;
}
これらの関数が使える状態で、
- ハッシュタグに関しては、 getTagCount("感謝"); と書けば 223 という数値が得られますし、 getTagCount("要望"); と書けば 181 という数値が得られます。
- カテゴリに関しては、getCatCount('情報'); と書けば 46 という数値が得られますし、getCatCount('つぼやき'); と書けば 142 という数値が得られます。
🧀Re:5701◆そうですね。私も時々表示確認するときに毎回気になってはいたんですが、「まあ……、いいかな……」と思って放置していました。(笑) 黒板スキンで常にご覧になっている方が居るとは予想していませんでしたので。^^; そのうちどうにかします。^^;
クロッカン、撮影するのは上下逆の方が良かったっぽい……? スタバサイトの写真を見ると。
🥮Re:5696◆ご要望をありがとうございます。詳しい背景事情もありがとうございます。とてもよく理解できました。ボタンラベルの最大文字数に上限を設けているのは「ラベルを指定しなかったときに長すぎるボタンになるのを防ぐため」ですが、6文字という上限値には特に意味はなく、なんとなく「それくらいで充分かな」と思っただけでした。^^; 「押して入力される文字列とボタンラベルを同じにしたい」という感覚も理解できますので、そう遠くないうちに『省略する文字数を自由に設定できる機能』を追加しようと思います。デフォルトで「大きすぎない上限値」があれば良いわけですから、動作を理解した上で好きに変更して頂く分には何の支障もありませんし。次のβ版は今月内(あと2日しかない……?)に出す予定でいますので間に合いませんが、その次のバージョンあたりでは実装できると思います。
※仕組みとしてシンプルで理想的なのは『ラベル用に指定した文字列は省略しない』動作ですが、ラベルと中身の分割にコロン記号「:」を使ってしまったので、「分割の意味で書かれたコロン記号」なのか「たまたま中身にコロン記号が含まれているだけ」なのかをシステム的に区別できないのでした。(^_^;)
🥮Re:5697◆ご要望をありがとうございます。ToDoリストには入れてありますので、そのうち対応します。
🥮ニコニコ動画を普段お使いの方々、「ニコニコ動画の埋め込みに対応しました」的な報告をするときに使っても大丈夫そうな、当たり障りのない(スクリーンショットを掲載しても他者の権利面で問題なさそうな)動画が何かありそうでしたら教えて下さい。
そんなのあるかな……?
🥮Re:5696◆ご要望をありがとうございます。詳しい背景事情もありがとうございます。とてもよく理解できました。ボタンラベルの最大文字数に上限を設けているのは「ラベルを指定しなかったときに長すぎるボタンになるのを防ぐため」ですが、6文字という上限値には特に意味はなく、なんとなく「それくらいで充分かな」と思っただけでした。^^; 「押して入力される文字列とボタンラベルを同じにしたい」という感覚も理解できますので、そう遠くないうちに『省略する文字数を自由に設定できる機能』を追加しようと思います。デフォルトで「大きすぎない上限値」があれば良いわけですから、動作を理解した上で好きに変更して頂く分には何の支障もありませんし。次のβ版は今月内(あと2日しかない……?)に出す予定でいますので間に合いませんが、その次のバージョンあたりでは実装できると思います。
※仕組みとしてシンプルで理想的なのは『ラベル用に指定した文字列は省略しない』動作ですが、ラベルと中身の分割にコロン記号「:」を使ってしまったので、「分割の意味で書かれたコロン記号」なのか「たまたま中身にコロン記号が含まれているだけ」なのかをシステム的に区別できないのでした。(^_^;)
🥮Re:5697◆ご要望をありがとうございます。ToDoリストには入れてありますので、そのうち対応します。
🥮ニコニコ動画を普段お使いの方々、「ニコニコ動画の埋め込みに対応しました」的な報告をするときに使っても大丈夫そうな、当たり障りのない(スクリーンショットを掲載しても他者の権利面で問題なさそうな)動画が何かありそうでしたら教えて下さい。
そんなのあるかな……?








